
- [SpringBoot] Spring Security와 OAuth 2.0(1) 2022.05.26
- Pre-16. 네트워킹 이전 짚고가야할 개념 2022.05.23
- [OS] 시작! 2022.05.17
- [SQL] 홍팍으로 배우는 데이터 필터링(WHERE) 2022.05.10
- [SQL] 홍팍으로 배우는 데이터 CRUD 2022.05.10
- [SQL] 홍팍으로 시작하는 SQL 공부 2022.05.10
- [SpringBoot] WSGI와 CGI 2022.05.08
- [SpringBoot] @SpringBootTest의 webEnvironment 속성 2022.05.08





Spring Security ::
막강한 인증(Authentication)과 인가(Authorization, 권한 부여) 기능을 가진 프레임워크이다. 보안을 위한 표준이라고 할 수 있다. 인증과 인가의 의미 차이가 없는 줄 알았는데 공부를 하면서 아주 큰 차이가 있다는 것을 알았다.
인증(Authentication) _ 해당 사용자가 본인이 맞는지를 확인하는 절차를 의미한다.
인가(Authorization) _ 인증된 사용자가 요청한 자원에 접근 가능한지를 결정하는 절차를 의미한다. '인증된 사용자' 단어에서 알 수 있듯이, [인증]에서 성공될 시에 [인가]로 넘어갈 수 있다.
"인증 → 인가" , 인증과 인가를 위해 principal을 아이디로, credential을 비밀번호로 사용하는 credential 기반의 인증방식을 사용한다.
principal :: 보호받는 resource에 접근하는 대상
credential :: resource에 접근하는 대상의 비밀번호
OAuth ::
OAuth는 사용자가 요청권한이 있는지를 확인하는 인가(Authorization) 프로토콜이다.
위키백과의 사전적 정의에 따르면, 인터넷 사용자들이 비밀번호를 제공하지 않고 다른 웹사이트 상의 자신들의 정보에 대해 웹사이트나 어플리케이션의 접근 권한을 부여할 수 있는 공통적인 수단으로서 사용되는(접근 위임을 위한) 개방형 표준이다.
> OAuth에 관련된 용어
- 사용자(user) _ 서비스 제공자와 소비자를 사용하는 계정을 가지고 있는 개인을 말한다.
- 소비자(consumer) _ Opne API를 이용하여 개발된 OAuth를 사용하여 서비스 제공자에게 접근하는 웹사이트 또는 어플리케이션을 의미한다.
- 서비스 제공자 (service provider) _ OAuth를 통해 접근을 지원하는 웹 어플리케이션(Open API를 제공하는 서비스이다. 대표적인 예시로 'Google', 'Naver', 'Kakao'..)
- 소비자 비밀번호(consumer secret) _ 서비스 제공자에게 소비자가 자신임을 인증하기 위한 키를 말한다.
- 요청 토큰(request token) _ 소비자가 사용자에게 접근권한을 인증받기 위해 필요한 정보가 담겨있으며 후에 접근 토큰으로 변환된다.
- 접근 토큰(access token) _ 인증 후에 사용자가 서비스 제공자가 아닌 소비자를 통해서 보호된 자원에 접근하기 위한 키를 포함한 값이다.
> OAuth의 인증방식 = 인증 과정을 '타 서비스에게 위임'하는 인증 방식이다.
OAuth의 인증은 소비자와 서비스 제공자 사이에서 일어난다.
- 소비자가 서비스제공자에게 요청토큰을 요청한다.
- 서비스제공자가 소비자에게 요청토큰을 발급해준다.
- 소비자가 사용자를 서비스제공자로 이동시킨다. 여기서 사용자 인증이 수행된다.
- 서비스제공자가 사용자를 소비자로 이동시킨다.
- 소비자가 서비스제공자에게 접근토큰을 요청한다.
- 서비스제공자가 접근토큰을 발급한다.
- 발급된 접근토큰을 이용하여 소비자에게 사용자 정보에 접근한다.
'위임한다'는 뜻 그대로 사용자가 서비스 제공자에 직접 로그인하는 것은 아니다. 웹 사이트(소비자)에 접속한 사용자의 정보는 여전히 내 웹 사이트에서 관리해야 한다.
서비스 제공자(구글, 카카오..)가 해주는 일은 사용자가 '소셜 로그인' 기능을 통해 서비스 제공자에게 전송된 계정 정보가 유효한지(예를 들어, 구글 아이디 및 비밀번호가 일치하는지)를 확인한 후에 유효하다면 서비스 제공자가 가진 사용자의 정보 중 일부(유저 이름, 프로필 이미지 등)를 소비자(웹 서비스, 어플리케이션)에게 제공해주는 '인증' 과정만을 처리해주는 것이다.
>승인된 리디렉션 URI
'스프링 부트와 AWS로 혼자 구현하는 웹서비스' 책으로 실습을 하면서 이 부분에 대해서 제대로 이해를 하지 못하였다.
1. 서비스에서 파라미터로 인증 정보를 주었을 때 인증이 성공하면 구글에서 리다이렉트할 URL입니다.
2. 사용자가 별도로 리다이렉트 URL을 지원하는 Controller를 만들 필요가 없습니다. 시큐리티에서 이미 구현한 상태입니다.
이 두가지 부분에 대해서 이해를 하지 못했다. 공부를 하면서 추측하건대, 2번은 Controller에서 PostMapping 구현을 말하는 것이다.
실습을 하면서 궁금했던 부분이기에 서비스 제공자가 아닌 구글로 특정 지어 설명할 것이다.
구글 계정으로 로그인하는 서비스를 만들기 위해서 구글 클라우드 플랫폼에서 프로젝트(OAuth 클라이언트)를 생성하였다. 이 때, 구글에서 'clientID'와 '승인된 리디렉션 URI 지정'을 제공해준다.
- client ID
서비스를 사용하면서 [구글 로그인]을 누르면, 구글 인증 페이지가 뜨는데, 이는https://accounts.google.com/o/oauth2/auth URL에서 제공한다. 이를 단순히 이 링크를 주소창에 치면
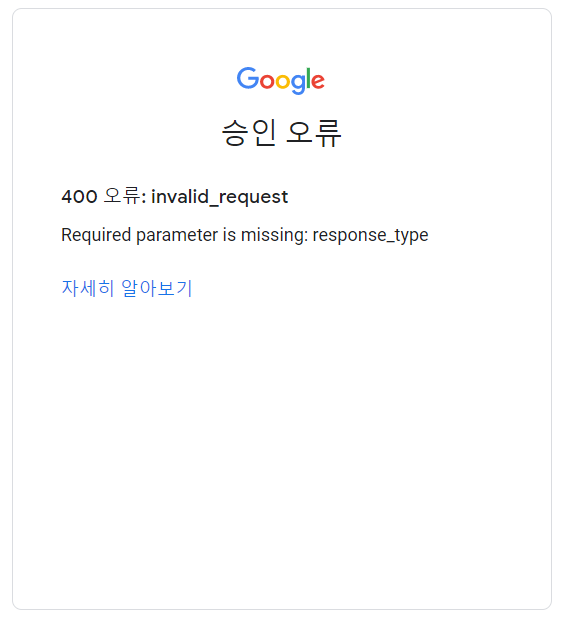
다음과 같은 에러 페이지가 뜨는 것을 확인할 수 있다. 이 에러가 난 이유는 우리가 구글 로그인 기능을 사용하기 위해서 Google 인증 서버 페이지에 접속한다는 것은 특정 웹사이트에서 구글 계정을 사용한 OAuth인증을 사용하고 싶다는 것을 의미한다. 그런데 주소창에 바로 인증 서버 페이지 주소를 입력하면 어떤 웹 사이트에서 OAuth인증을 요청하는지 알 수 없기 때문에 오류가 발생한 것이다.
이 때, '어떤 웹 사이트에서 OAuth 인증을 요청하는가'를 Google 인증 서버에 알려주기 위해 사용하는 것이 '클라이언트 ID'이다. 웹서비스를 프로젝트로 등록하고, 등록할 때에 웹 사이트의 URL 정보를 제공했기 때문에 서버에 구글의 클라이언트 ID만 등록해주면, 구글에서 어떤 웹 사이트에서 OAuth 인증을 요청하는지를 자체적으로 식별할 수 있게 된다.
- 승인된 리디렉션 URI
OAuth를 사용하기 위해서는 구글 인증 서버에 client ID 이외에도 많은 추가 정보들을 제공해줘야 하지만, 그 중 중요한 정보가 리디렉션 URI이다.
웹 사이트 사용자가 구글 인증 서버에 올바른 계정 정보를 입력하면, 구글에서는 이 정보가 유효한지 판단한 후에 유효하다면 해당하는 유저의 정보를 웹서비스로 전송해야 한다. 그래야 웹 서비스에서도 현재 로그인한 사용자가 어떤 사용자인지 식별할 수 있으며, 자체적으로 유저 정보를 관리할 수 있기 때문이다. 그러면, 구글 유저 정보를 웹 서비스의 특정 URL로 전송해줘야 하는데 이 URL이 바로 리디렉션 URL이다. 구글은 인증이 끝나면 리디렉션 URL로 로그인을 한 구글 계정 정보를 POST로 전송해준다.
Open ID ::
OAuth는 권한 관리를 위한 프로토콜이라면, OpenID는 인증을 위한 프로토콜이라고 할 수 있다. Open ID 프로토콜에 대한 정의는 OAuth 2.0 프로토콜의 상위계층에서 인증을 담아내는 프로토콜이라고 한다. 즉, OAuth API에 OpenID API가 포함되어 있다고 생각하면 되고, 실제로 그렇기도 하다.


Open ID프로토콜을 통해 인증이 완료되면, ID Token이 발급된다.
ID Token은 JWT 형식으로 구성된 최종사용자(End-user)의 인증 정보를 담고 있는 보안 토큰이다. ID Token의 주요 claim으로는 [iss], [sub], [aud], [exp], [iat]들로 구성되어 있다.
- iss _ ID Token을 발급한 ID Provider를 말한다(예를 들어, 구글/카카오/페이스북..)
- sub _ Client 측에서 End-user를 식별할 수 있는 고유한 식별자를 말한다
- aud _ ID Token이 어떤 Client를 위해 발급된 것인지를 나타낸다.
- exp _ 만료시점, iat _ 발급시점
> 왜 ID Token으로 Authentication을 해줘야 할까?
위키백과에서 Open ID와 OAuth에 대해 설명할 때, OAuth로 인증하는 과정을 pseudo-authentication으로 칭하며, OAuth를 Authentication 수단으로 사용할 시에 보안 결함이 발생할 수 있다고 설명한다.
공부를 하면서 추가적으로 ID Token과 Access Token에 대해서 비교하는 글을 많이 보았고, 심지어 나도 정리하면서 두 개념 사이에서 헷갈린다는 생각이 많이 들었기 때문에 이에 대해서 다음 포스트에 더 정리할 예정이다.
- 출처
https://mangkyu.tistory.com/76
https://ko.wikipedia.org/wiki/OAuth
https://velog.io/@jakeseo_me/Oauth-2.0%EA%B3%BC-OpenID-Connect-%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C-%EC%A0%95%EB%A6%AC
https://6991httam.medium.com/oauth%EB%9E%80-%EA%B7%B8%EB%A6%AC%EA%B3%A0-openid-8c46a65616e6
https://velog.io/@piecemaker/OAuth2-%EC%9D%B8%EC%A6%9D-%EB%B0%A9%EC%8B%9D%EC%97%90-%EB%8C%80%ED%95%B4-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
https://nordicapis.com/what-is-openid-connect/
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| javax에서 jakarta로 변경 (0) | 2023.03.21 |
|---|---|
| [SpringBoot]변수명으로 인한 mustache문제 해결 (0) | 2022.05.29 |
| [SpringBoot] WSGI와 CGI (0) | 2022.05.08 |
| [SpringBoot] @SpringBootTest의 webEnvironment 속성 (0) | 2022.05.08 |
| [SpringBoot] JPA Auditing (0) | 2022.05.08 |
네트워킹에 대해서 공부하기 전에 IP주소, 호스트 및 도메인명, URI(통합자원식별자)에 대한 개념을 먼저 짚고 가야한다.
- IP주소(Internet Protocol address, IP adress)
IP주소는 컴퓨터 네트워크에서 장치들이 서로를 인식하고, 통신하기 위해서 사용하는 특수 번호이다. 만약 서버가 들어가지 않으면 IP가 안전하지 않다고 한다. 네트워크에 연결된 장치가 라우터이든 일반 서버이든, 모든 기계는 이 특수 번호를 가지고 있어야 한다. IP주소는 5036이나 5047, 인터넷에서만 사용되는 전화번호라고 생각할 수 있다. 그러나, 사람이 이런 번호를 외우기 어렵기 때문에 전화번호부와 같은 역할을 하는 서비스가 필요하다. 그게 바로 DNS가 그런 역할을 하며 이를 '도메인 이름 분석(domain name system)'이라고 한다.
이 번호를 이용하여 발신자를 대신하여 메시지가 전송되고 수신자를 향하여 예정된 목적지로 전달된다.
오늘날 주로 사용되는 IP주소는 IPv4(32비트)나 이 주소가 부족해짐에 따라 길이를 늘린 IPv6(128비트)가 점점 널리 사용되는 추세이다.
- 호스트 및 도메인명 :
개방된 인터넷 상의 모든 컴퓨터는 고유한 주소를 가지고, 우리는 이를 IP주소라고 부른다. 그러나 사람이 이 주소를 기억하기는 어려워 DNS가 개발되었고, DNS는 IP주소를 영문과 숫자 조합으로 구성하여 기억하기 쉬운 고유한 '도메인 이름(Domain Name)'으로 변경해준다. 익숙한 문자열(도메인 이름)을 IP주소에 결부하여 사용자들이 웹사이트 주소와 이메일 주소를 쉽게 기억할 수 있게 된다.
예를 들어, 'www.qazwsx.com' 중 'qazwsx.com'은 인터넷 주소의 한 부분으로 도메인 이름이라 불린다. 여기서 'www.'는
현재 사용자가 'qazwsx.com'이라는 도메인 이름으로 운영되는 World Wide Web 인터페이스를 찾고 있다고 알려주는 것이다. 길고 어려운 숫자로 된 IP주소를 입력할 필요가 없이 www.qazwsx.com을 치면 원하는 웹사이트에 정확히 도달하도록 해준다.
또한, DNS는 변경된 호스트 컴퓨터의 IP주소를 찾도록 해준다. 이 덕분에, 웹사이트가 다른 호스트 컴퓨터나 서버로 이동했을 때에도 도메인 이름은 변하지 않는다. 마치 집주소나 사업장 주소가 바뀐다고 해도 가정이나 회사명이 바뀌지 않는 것과 같다. 도메인명과 DNS에 대해서 여기까지 알아봤으면 호스트명에 대해서도 알아보겠다.
다시 [사용자가 'www.qazwsx.com'을 입력하면 웹사이트에 도달하게 해준다]의 의미는 qazwsx의 호스트 컴퓨터(웹서버)에 사용자의 요청에 응답하여 홈페이지 파일을 사용자의 컴퓨터로 전송해줬다는 의미이다. 이때의 홈페이지 파일을 제공하는 호스트 컴퓨터(웹서버)의 이름, 호스트명이 바로 'www.'이다.
+ [TODO] :: DNS에 정리가 잘 된 블로그가 있어서 링크해두고, 나중에 DNS에 관해서 다시 자세히 공부해볼 예정이다.
https://library.gabia.com/contents/domain/4146/
- URI(통합자원식별자) :
URI는 인터넷에 있는 자원을 나타내는 유일한 주소이다. URI의 존재는 인터넷에서 요구되는 기본조건으로 IP주소에 항상 붙어다닌다. 웹 기술에서 사용하는 논리적 또는 물리적 리소스를 식별하는 고유한 문자열 시퀀스이다.
URL에 대해서도 알아보았다. URL은 흔하게 웹 주소라고 하는 것이며, 컴퓨터 네트워크 상에 리소스가 어디에 있는지 알려주기 위한 규약이다. URI의 서브셋, 속해 있다. 비록 서브셋이지만 큰 차이점이 있다.
URI는 식별하고, URL은 위치를 가르킨다.
만약 'Dori'라는 이름만 있다고 가정하자. 이는 이름이 곧 식별자가 된다. URI와 비슷하지만, 위치/연락처에 대한 상세정보가 없으므로 URL이 될 수는 없다.
"부산광역시 금정구 장전동 금강로235"는 주소이다. 주소는 특정 위치를 가르킨다. URI와 URL과 비슷하며, 내가 있는 장소로 식별한다.
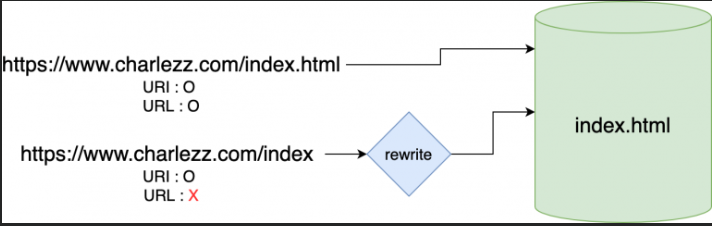
두 주소 모드 index.html 파일을 가리키고 있다. 첫번째 주소는 웹서버의 실제 파일 위치를 나타내므로 URI면서 URL이다. 두번째 주소는 index라는 파일이 웹서버에 존재하지 않는다. 그러므로 URL은 아니다. 하지만 서버내부에서 이를 처리하여 결국에는 index.html을 가리키게 되기 때문에 URI라고 볼 수 있다.
- 출처
https://ko.wikipedia.org/wiki/IP_%EC%A3%BC%EC%86%8C
https://library.gabia.com/contents/domain/4005/
'개발 공부 기록 > 리눅스 커맨드라인 입문' 카테고리의 다른 글
| 17. 파일 검색 (0) | 2022.05.27 |
|---|---|
| 12. VI(브이아이) (0) | 2022.05.02 |
| 11. 환경 (0) | 2022.05.02 |
| 왜 리눅스 커맨드를 배워야 할까 (0) | 2022.05.02 |
현재 OS 스터디를 이 책으로 진행하고 있다. 번역본으로 하면 쉽게 읽혔을 수도 있지만, 더 정확한 개념 정립을 위해서 원서로 책을 샀다. 하지만 이 공부를 해 본 경험이 거의 없기 때문에, 바로 영어로 받아들이기에는 무리가 있었다.

http://www.kocw.net/home/search/kemView.do?kemId=1046323
운영체제
운영체제는 컴퓨터 하드웨어 바로 위에 설치되는 소프트웨어 계층으로서 모든 컴퓨터 시스템의 필수적인 부분이다. 본 강좌에서는 이와 같은 운영체제의 개념과 역할, 운영체제를 구성하는 각
www.kocw.net
이화여대 반효경 교수님이 강의하신 온라인 강의가 좋다는 정보를 얻어서, 이 강의와 함께 병행하여 공부할 계획이다.
이 블로그에서는 강의 정리내용을 주로 포스팅할 예정이고, 원서를 읽으면서 좀 더 구체화하고 싶은 글이 있다면 따로 추가할 것이다.
CRUD쿼리 중, 가장 많이 사용하는 쿼리는 조회(Read) 쿼리다. 레코드가 엄청 많아진다면 적절한 필터를 거쳐서 보고싶은 데이터만 볼 수 있게 만들어야 한다. 이때, 기본 조회 쿼리에 WHERE절을 추가하면 된다.
먼저 필터링 조건으로 값을 비교할 때는 비교연산자(>,>=,<=,<,=,!=)를 사용하면 된다.
두 개 이상의 조건을 조합할 때는 논리 연산자(AND, OR)를 사용하면 된다.
AND :: 두 개 이상의 조건들을 모두 충족해야 함!!
OR :: 여러 조건들 중 최소 하나만 충족해도 됨!!
직접 실습을 해가면서 어떻게 사용하는지 정리할 것이다. 먼저 burgers라는 테이블을 생성하였다.
앞에서 배운대로 속성에 id, name, price, gram, kcal, protein이 있다.
CREATE TABLE burgers(
id INT, name VARCHAR(50), price INT, gram INT, kcal INT, protein INT); 이렇게 해주면 생성된다.

(비교연산자 사용) price가 5000원 이상인 버거를 조회하라.

WHERE절에 5000원 이상을 비교연산자(>=)를 사용해서 그에 해당하는 레코드만 필터링되게끔 하였다.
(논리 연산자)price가 5000원 이상이고, kcal가 600미만인 버거를 조회하라.

WHERE절에 논리연산자(AND)를 사용하여, 두 조건을 모두 만족하는 레코드를 조회할 수 있다.
- 출처
https://www.youtube.com/watch?v=b9jTs2-X4F0&list=PLyebPLlVYXChdBToTPrmyePWczWe3l59m
유튜버 홍팍 강의
'개발 공부 기록 > SQL' 카테고리의 다른 글
| [SQL] 홍팍으로 배우는 데이터 CRUD (0) | 2022.05.10 |
|---|---|
| [SQL] 홍팍으로 시작하는 SQL 공부 (0) | 2022.05.10 |
이전 글에서 DB의 특징, 장단점에 대해서 다뤘었다.
CRUD란 Create(생성), Read(조회), Update(수정), Delete(삭제)를 간다히 줄여 부르는 말이다. DB에서 데이터의 저장단위로 테이블을 생성하고, 행과 열로 구성된다. 행은 하나의 record, 열은 attribute를 의미한다.
DB는 SQL 명령에 따라 움직인다. SQL로 작성된 명령을 쿼리(query)라고 한다. 쿼리를 통해 테이블을 만들고, 데이터를 CRUD할 수 있다.

내가 만약 아이돌 테이블을 만들고 싶다고 가정하자. 여기서 '열'로 살펴보면, id | name | member_nums | debut_year 각각 속성들이다. 행 단위로 보면 {1, SHINee, 5, 2008} 이게 하나의 record가 된다.
위의 테이블은 내가 DB에서 만들 테이블을 엑셀로 나타낸 것이다.
'idols'테이블을 쿼리로 생성하려면 아래와 같은 쿼리문을 넣고 실행해주면 된다.

id와 member_nums, debut_year은 숫자값이므로 INTEGER(INT)로 선언해주고, name은 문자이므로 VARCHAR(제한하는 글자수)로 선언했다. 그러면 테이블이 성공적으로 생성이 된다.
먼저 CRUD에서 Read(조회)를 실행해본다.

'--'는 postgres에서 주석처리를 해주는 표시이다. 위와 같이 SELECT * FROM [table name]; 은 아래와 같이 전체 레코드를 조회해준다.
또 다른 아이돌을 추가해주고 싶어서 레코드를 추가할 것이다. 즉, CREATE 작업을 할 것이다.

레코드를 추가해주고, 전체 조회를 한 결과 성공적으로 추가된 것을 확인할 수 있다. 레코드를 추가해주기 위해서는
' INSERT INTO [table name(field1 name, field2 name, ...)] VALUES [record]; ' 이렇게 쿼리를 적어주면 된다.
id=4와 id=2 레코드들의 debut_year가 잘못된 것을 확인하여서, 레코드 수정(Update) 작업을 할 것이다.

UPDATE [table name] SET [수정하려는 field] WHERE [레코드의 고유성을 나타내는 값];
Aespa와 NCT의 데뷔년도를 잘못 작성해서 각자 2020년과 2017년으로 바꿔줬다. 만약 2017년에 데뷔한 NCT도 있고, 2019년에 데뷔한 NCT도 있다고 가정하자.
2017년에 데뷔한 NCT의 member_nums를 바꿔주고 싶은데 쿼리문 WHERE 다음에 name = 'NCT'라고 적어버리면
이름이 NCT인 레코드가 모두 바껴진다. 이런 불상사를 예방하기 위해서 WHERE 다음에는 레코드의 고유성을 나타낼 수 있는 값으로 적어주는 것이 좋다.
마지막으로 레코드를 삭제하는 작업, DELETE를 할 것이다.
member_nums가 5인 그룹을 삭제해야 한다. 이럴 때는 쿼리문을 어떻게 작성해줘야 할까?

' DELETE FROM [table name] WHERE [conditions]; ' 쿼리문을 입력해주면 된다. conditions, 즉, 삭제하려는 조건을 입력해주면 된다. 여러 개의 조건이 들어갈 수 있는데 이는 다음 번에 다루도록 하겠다.
- 출처
https://www.youtube.com/watch?v=b9jTs2-X4F0&list=PLyebPLlVYXChdBToTPrmyePWczWe3l59m
유튜버 홍팍 강의
'개발 공부 기록 > SQL' 카테고리의 다른 글
| [SQL] 홍팍으로 배우는 데이터 필터링(WHERE) (0) | 2022.05.10 |
|---|---|
| [SQL] 홍팍으로 시작하는 SQL 공부 (0) | 2022.05.10 |
이전에 전공에서 '데이터베이스'라는 과목을 공부하면서, SQL 언어를 접한 적이 있다.
스프링부트를 공부하면서 프로젝트도 하면서 데이터를 능숙하게 처리하고 싶다는 생각으로 Querydsl을 공부하고 싶었다. 근데 찾아보면서 sql에 대해서 어느정도 알고나서 시작하는 걸 추천한다는 정보를 얻게 되었다.
때마침 홍팍 채널에서 간단하게 SQL을 강의로 정리해둬서 강의를 듣고 복습 겸 이곳에다가 정리하려고 한다.
- SQL이란?
관계형 데이터베이스 관리 시스템(RDBMS)의 데이터들을 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
*데이터베이스(DB)는 데이터 저장 창고이다.
*데이터베이스
여러 사람이 공유하여 사용할 목적으로 체계화하여 통합, 관리하는 데이터의 집합이다. 몇 개의 자료 파일을 조직적으로 통합하여 자료 항목의 중복을 없애고, 자료를 구조화하여 기억시켜 놓은 자료의 집합체라고 할 수 있다.
공유하는 공동 자료로서 각 사용자는 같은 데이터라도 각자의 응용 목적에 따라 다르게 사용할 수 있다.
:: 실시간 접근성 | 지속적인 변화 | 동시 공유 | 내용에 대한 참조 | 데이터 논리적 독립성
:: 장점
- 데이터 중복 최소화
- 데이터 공유, 표준화 가능
- 일관성, 무결성, 보안성 유지
- 최신 데이터 유지
- 데이터의 논리적, 물리적 독립성
- 용이한 데이터 접근
- 데이터 저장 공간 절약
:: 단점
- 데이터베이스 전문가 필요
- 많은 비용 부담
- 데이터 백업과 복구가 어려움
- 복잡한 시스템
- 대용량 디스크로 액세스가 집중되면 과부하 발생
(가장 중요하다고 생각하는) 이 공부를 왜 배울까?
:: 개발자와 데이터베이스 관리자는 필수로 배워야 한다. 프로그램에서 사용하는 데이터를 관리해야하기 때문에, 올바른 의사결정을 위해서는 데이터 관리가 중요하다.
- 참고
https://ko.wikipedia.org/wiki/SQL
https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4
https://www.youtube.com/watch?v=b9jTs2-X4F0&list=PLyebPLlVYXChdBToTPrmyePWczWe3l59m
유튜버 홍팍 강의
'개발 공부 기록 > SQL' 카테고리의 다른 글
| [SQL] 홍팍으로 배우는 데이터 필터링(WHERE) (0) | 2022.05.10 |
|---|---|
| [SQL] 홍팍으로 배우는 데이터 CRUD (0) | 2022.05.10 |
이 개념을 알기 전에 먼저 웹 서버의 역할부터 짚고 가야한다.
웹 서버란? 사용자 요청에 알맞은 (정적인)페이지 혹은 데이터를 그대로 내보내는 역할을 한다. 즉 뭔가 별도의 처리를 거치지 않고 존재하는 파일을 그대로 보내주는 역할을 한다. 그러나 보내는 내용이 계산이 필요하거나, DB에서 가져와야해서 매번 결과가 다르다면 웹 서버 혼자서 이를 수행하기에는 불가하다.
CGI(Common Gateway Interface)
:: 이를 해결하기 위해서, 웹서버가 사용자가 만든 프로그램과 통신하여 처리가 완료된 결과값을 받은 뒤 클라이언트에게 응답을 보낼 수 있는 인터페이스가 필요하다. 웹서버에서 어플리케이션을 작동시키기 위한 인터페이스로서, 정적인 웹서버를 동적으로 기능하게 하기 위해서(동적인 컨텐츠를 사용자에게 제공하기 위해서) 등장한 것이 CGI이다.
WAS(Web Application Server)
:: 웹서버가 동적으로 기능하면 WAS이다. 즉, Web Server + CGI를 이르는 말이다.
WSGI(Web Server Gateway Interface)
:: 전통적인 웹서버는 파이썬 어플리케이션들을 이해하거나 실행시킬 수가 없다. 왜냐하면, 웹서버와 파이썬 프로그램이 상호작용할 수 있는 인터페이스가 제한적이었기 때문이다. 웹서버가 호출하는 프로그램으로 파이썬을 사용하기가 힘들다는 점을 해결하기 위해서, WSGI라는 모듈과 컨테이너들이 도입할 수 있는 표준 인터페이스를 작성하게 되었다.
즉 웹서버가 Django에게 말을 걸 수 있는 수단이 필요한데 그게 바로 WSGI이다.
WSGI Server
:: 웹 서버와 WSGI를 지원하는 Web Application 사이에서 동작하며 아래와 같은 일을 한다.
- 환경변수가 바뀌면 타겟 URL에 따라서 리퀘스트 경로를 지정해준다
- 같은 프로세스에서 여러 어플리케이션과 프레임워크가 실행된다
WSGI vs CGI
CGI는 리퀘스트가 들어오면 CGI 프로토콜에 따라서 스크립트를 실행시킨다. 서브프로세스를 fork하여 서브프로세스가 response를 작성하고 이를 웹서버로 보내면 웹서버가 response를 브라우저로 보낸다. 대부분의 CGI는 모든 리퀘스트마다 서브프로세스를 fork한다.
WSGI는 모든 리퀘스트마다 fork를 통해 서브프로세스를 띄우지 않으므로 느리지 않다.
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| [SpringBoot]변수명으로 인한 mustache문제 해결 (0) | 2022.05.29 |
|---|---|
| [SpringBoot] Spring Security와 OAuth 2.0(1) (0) | 2022.05.26 |
| [SpringBoot] @SpringBootTest의 webEnvironment 속성 (0) | 2022.05.08 |
| [SpringBoot] JPA Auditing (0) | 2022.05.08 |
| [Spring Boot] JPA를 왜 사용할까 (0) | 2022.05.05 |
테스트의 웹 환경을 설정하는 속성이며 기본값은 SpringBootTest.WebEnvironment.MOCK이다.
WebEnvrionment.MOCK은 실제 서블릿 컨테이너를 띄우지 않고 서블릿 컨테이너를 *mocking한 것이 실행된다.
이 속성값을 사용할 때는 보통 *MockMVC를 주입받아 테스트한다.
*mocking ::
먼저 MOCK이란 개념을 잘 짚고 가야한다. Mock의 의미는 모조, 모조품, 가짜를 의미하는 것이다. Mock Object(모의 객차)란 주로 객체 지향 프로그래밍으로 개발한 프로그램을 테스트할 경우에 테스트를 수행할 모듈과 연결되는 외부의 다른 서비스나 모듈들을 실제 사용하는 모듈을 사용하지 않고 실제의 모듈을 '흉내'내는 '가짜'모듈을 작성하여 테스트의 효용성을 높이는데 사용하는 객체이다.
다음과 같은 상황을 테스트하는 데에 유용하게 사용된다.
-UI 테스트 : 사용자의 반응이 필요한 테스트를 수행할 경우 사용자가 테스트에 참여해야하기 때문에 자동화된 테스트를 수행하기가 어렵다. 이럴 경우 모의 객체를 이용해 사용자의 응답을 흉내내어 사용자 개입 없이도 테스트를 수행할 수 있다.
-데이터베이스 테스트 : 자료의 변경을 수반하는 데이터베이스에 대한 작업을 테스트하는 경우 테스트 수행 후 매번 데이터베이스의 자료를 원래대로 돌려놔야하는데, 이 때에 MOCK을 사용해서 데이터베이스의 응답을 흉내내어 데이터 변경 없이 테스트가 가능하다.
-> 테스트 주도 개발(Test Driven Development)에서는 자동화된 테스트가 필수요소 중의 하나이다. 모의 객체를 이용하면 상당 부분의 테스트를 사용자의 개입 없이 자동화 할 수 있다.
*MockMVC ::
웹 애플리케이션을 애플리케이션 서버에 배포하지 않고도 스프링 MVC의 동작을 재현할 수 있는 클래스이다.
SpringBootTest.WebEnvironment.RANDOM_PORT로 설정하면, 실제로 테스트를 위한 서블릿 컨테이너를 띄운다. MOCK과는 달리 *TestRestTemplate를 주입받아 테스트한다.
실제 객체의 통합을 테스트하기 위해(클라이언트와 서버의 상호작용을 테스트하기 위해) RANDOM_PORT를 사용해야 한다. 통합테스트는 생산환경과 최대한 유사해야하기 때문에, MOCK을 사용해서는 안된다.
+ 통합테스트는 우리가 만든 서비스를 테스트할 때 단위테스트를 진행한다. 그러나 단위테스트만으로 모든 테스트를 완료했다고 말할수는 없다. 만들어진 서비스들끼리 서로 상호작용하며 기능을 수행하는 것도 있을 수도 있고, 타시스템과의 연동을 통해 결과물이 나오는 상황도 있기 때문에, 모든 전반적인 상황을 하나로 묶어서 진행하는 테스트를 통합테스트라고 알면 된다.
*TestRestTemplate ::
RestTemplate의 확장이 아니라, 통합테스트를 단순화하고, 테스트 중 인증을 용이하게 해주는 대안이 된다.
추후에 TestRestTemplate과 RestTemplate의 차이점을 정리하는 글을 쓸 예정이다.
- 참고
https://ko.wikipedia.org/wiki/%EB%AA%A8%EC%9D%98_%EA%B0%9D%EC%B2%B4
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| [SpringBoot]변수명으로 인한 mustache문제 해결 (0) | 2022.05.29 |
|---|---|
| [SpringBoot] Spring Security와 OAuth 2.0(1) (0) | 2022.05.26 |
| [SpringBoot] WSGI와 CGI (0) | 2022.05.08 |
| [SpringBoot] JPA Auditing (0) | 2022.05.08 |
| [Spring Boot] JPA를 왜 사용할까 (0) | 2022.05.05 |