
- go.mod의 unresolved dependency 문제 해결.txt 2024.08.17
- feign을 많이 활용했지만 자세히 모르는 것 같아서 반성함.txt 2024.08.17
- Golang으로 사이드 프로젝트 시작해보기.txt 2024.08.15
- 왜 dto에서 항상 @Getter와 @NoArgsConstructor를 붙여줘야 할까? 2023.03.26
- 왜 외래키가 있는 곳을 연관관계의 주인으로 잡을까? 2023.03.21
- javax에서 jakarta로 변경 2023.03.21
- [SpringBoot]변수명으로 인한 mustache문제 해결 2022.05.29
- 17. 파일 검색 2022.05.27





ent Schema를 생성한 후, Field의 docs를 읽으면서 어떻게 속성을 정의해주는지 확인하려고 했습니다.
Field를 클릭했는데, Cannot find declaration to go to 라고 뜨면서 import가 되지 않았다는 걸 깨달았습니다ㅜ
go.mod를 가니 unresolved dependency 80개가 우르르 떴습니다.
mac 기준 일반적인 해결방안은 Settings > Go > Go Modules > Enabling Go modules intergration 하는 것이었습니다.
추가로 Go Path > deselect index entire GOPATH 인 것도 있었습니다.
이 모든 것들이 기본적으로 되어 있는 상황이었어서, 또 다른 해결방안을 찾아봐야 했습니다.
제 프로젝트에서는 .idea 디렉토리가 존재했습니다. 여기에는 .gitignore 파일, 등등 다양한 파일이 있었습니다.
.gitignore 파일은 루트로 이동시키고, .idea 디렉토리를 삭제하였습니다. (다른 파일은 사용하지 않는 파일이라 판단)
그리고 다시 해당 프로젝트를 열었더니 의존성을 처음부터 설치하면서 unresolved dependency 문제를 해결할 수 있었습니다.
'개발 공부 기록 > Golang + Gin' 카테고리의 다른 글
| Golang으로 사이드 프로젝트 시작해보기.txt (0) | 2024.08.15 |
|---|
문제 상황
Upstage의 solar LLM API를 연결하여 AI 챗 기능을 구현하려고 했습니다. Feign client로는 카카오 로그인과 개발 중인 서비스의 AI 모델들을 이용하여 호출하도록 구현해놓은 상황이었습니다.
그동안 Feign을 잘 몰랐어도 외부 API를 호출하기 쉬웠고, 이번 LLM 모델 API도 Feign을 이용하여서 구현할 계획이었습니다.
API 호출에 필요한 설정은 물론 응답 정보를 담는 dto, 호출할 수 있도록 하는 controller를 모두 만들어놓고 포스트맨으로 실행했는데, 예상과 달리 아래와 같은 로그가 남게 되는 것이었습니다.

원인 분석 과정
1. 실제 API 응답을 받는 dto 멤버변수명 확인 필요
Unknown Source...?? '외부 API에서 응답을 받아와서 직렬화할 때 문제가 발생하는 것인가?'하고 dto 변수명들을 꼼꼼히 훑어봤습니다. 변수명이 틀린 부분은 없었습니다.
2. API 호출 설정에 대한 의심 필요 -> 직접 curl 요청
직접 터미널에서 curl 요청을 해도 정상적인 응답을 받았습니다.
3. Bean 주입이 제대로 되었는지 확인 필요
당시에 Feign을 활용한 다른 서비스와 동일하게 설정했음에도 안됐어서, 이 부분에 대해서는 체크하지 못했습니다.
해결 방안
getChatResult 메서드는 feign client에 선언된 메서드를 호출합니다. 그리고 필요한 데이터만 정의한 dto에 맞게 다시 response를 가공해서 controller단에 반환해주는 역할을 합니다. 근데 저기서 Unknown Source라고 에러가 나타나니, 빈이 제대로 주입되지 않았나?하는 의문이 생겼습니다. 그러나 동일하게 만들어진 다른 곳에서는 정상 동작을 하고 있었기 때문에 원인을 찾기가 힘들었습니다(이 때 많은 현타가 왔습니다..ㅜ 제대로 알고 활용한 게 아니라는 반성이 들었습니다..ㅜ)
당시 대회 과제를 빠르게 제출해야 했기 때문에, 원인 분석에 지체할 시간이 없었습니다. Feign은 동적 프록시를 사용하여 API 호출을 간단하게 해줍니다. 당시에 Feign client를 찾을 수 없다고 했기 때문에, 프록시에 의존하는 것이 아니라 직접 http 클라이언트를 만들어야 했습니다. 그래서 okhttp 라이브러리를 활용했고, 정상적인 응답을 받을 수 있었습니다.
배경
이번 JUNCTION ASIA 2024에 참여하게 되었습니다. 해커톤에서 어떤 챌린지를 해보는게 좋을까 고민하였습니다.
처음에는 높은 완성도를 위해서 개인적인 템플릿이 많이 갖춰져있는 Java로 구현하려고 했습니다. 그러나 실무에서 사용하는 Golang으로 서버를 구축하고 서비스를 만들어보고 싶다는 욕심이 계속 생겨서, Go로 서버를 구축하기로 결정했습니다.


해커톤 전까지 인프런에서 Go 서버 구축 관련한 기초 강의를 들으며, 어떤 라이브러리를 쓸지에 대해 미리 생각해봤습니다.
아래 링크의 강의를 학습하며 미리 구축하고자 했습니다.
그러나 모든 것들을 강의에 맞춰 진행하지는 않았습니다. 강의에서는 DB 연동을 하지 않고 있기 때문에, 실제 개발을 하는데에 크게 도움이 되지는 않습니다. 프로젝트 골격을 만드는 데에는 많은 도움을 줬습니다.
그래서 프레임워크/ORM/의존성 주입 관리를 할 때 어떤 기술을 사용할 지에 대해 고민하였습니다.
Golang을 통한 백엔드 개발 및 환경 구축하기 강의 | July - 인프런
July | Golang을 통해서 CRUD를 어떻게 구성하는지는 물론, 프론트엔드와 협업할 때 사용 가능한 PostMan 활용법과 Repository 관리 및 환경 구축까지! 실제 실무에서 필요한 지식을 담았습니다., [사진]Gola
www.inflearn.com
선택한 기술들(gin + Ent + fx)
프레임워크는 gin으로 사용할 것입니다.
레퍼런스가 작은 Go 특성을 생각하여, 그나마 레퍼런스를 빠르게 찾을 수 있도록 대중적인 프레임워크를 선택했습니다.
ORM 기술로는 ent를 사용할 것입니다.
실무에서 GORM을 사용하면서 ORM이라기보다는 직접 쿼리를 작성해야 하는 경우가 많아 JPA와 비교했을 때 불편함을 느꼈습니다. 특히, RecordNotFound() 메서드의 경우, 데이터가 있을 때 false를 반환하는데, 메서드 이름과 동작이 직관적이지 않아 불만이 있었습니다. JPA를 사용하다가 GORM으로 넘어오니 직접 쿼리를 작성해야 하는 상황이 자주 발생해 ORM의 편리함을 충분히 느끼지 못했습니다. 그래서 이번에는 Ent를 사용해보았습니다. Ent는 다양한 메서드를 제공하며, 코드 가독성이 뛰어나 선택하게 되었습니다.
의존성 주입 관리 기술로는 uber의 fx를 사용할 것입니다.
처음에는 이게 왜 필요하지?라는 생각이 들었는데, 위의 강의를 따라치며 만든 코드와 [블로그](https://www.essential2189.dev/go-fiber-boilerplate) 글을 비교해보며, 의존성 주입 관리 기술이 필요하다는 생각이 들었습니다.
블로그의 본문 내용에 따라 fx를 선택하기로 했습니다.
목표
Go 코드나 Go 프로젝트가 Java처럼 보이지 않도록 Java에서 벗어난 프로젝트처럼 보이고 싶었습니다.
갓 취업을 했을 때 저는 Java 신봉자였습니다. Java만큼 객체 지향에 대한 레퍼런스가 많고, 객체지향이 잘 되도록 구성된 언어는 없다고 생각했고, 다른 언어는 이런 점을 따라가야 한다고 생각했습니다.
그래서 회사 코드를 볼 때 'Java였다면..'라는 생각을 놓을 수가 없었습니다. 어떤 부분이든 Java 기준을 잣대로 코드를 리팩토링하려고 했습니다. 업무를 하면서 느낀 점은 언어마다의 특성을 이해하고 그 언어의 특징을 살려줘야 한다는 생각이 들었습니다.
이번 사이드 프로젝트를 Go로 진행하면서 목표를 달성하고자 했습니다. 나아가서 Go를 이용한 프로젝트 템플릿이 없다는 걸 많이 깨달아 이번 기회에 Go로 프로젝트를 쉽게 시작할 수 있는 템플릿을 만들어보고자 했습니다.
'개발 공부 기록 > Golang + Gin' 카테고리의 다른 글
| go.mod의 unresolved dependency 문제 해결.txt (0) | 2024.08.17 |
|---|
Web application 개발을 계속 하면서 request-POJO-response로 데이터가 흘러가는 것을 파악했습니다.
이를 위해서 dto에 항상 의무적으로 @Getter와 @NoArgsConstructor를 붙여가며 기능을 구현했습니다.
이렇게 json 데이터를 dto 객체로 변환하여 작업한 후에 처리된 데이터를 다시 json 형식으로 변환하는 일은 누가 하는지에 대해 궁금했습니다.
이런 일을 주로 처리하는 라이브러리는 SpringBoot starter에 포함되어 있는 jackson 라이브러리가 합니다.
Jackson라이브러리에 대해 좀 더 자세히 알아보고, 왜 @Getter와 @NoArgsConstructor를 붙여줘야 하는지 파악하려고 합니다.
jackson은 json 데이터 구조를 손쉽게 처리해주는 라이브러리입니다.
dto 객체를 json으로 변환하는 것을 직렬화라고 하고, json 데이터를 dto로 변환하는 것을 역직렬화라고 합니다.
@Getter
@NoArgsConstructor
public class ReviewUpdateDto {
private Long id;
private String review;
}
저희 프로젝트에서 dto객체의 property는 모두 private으로 선언했습니다.
이렇게 public이 아닌, private 또는 protected로 선언하는 경우에는 getter를 같이 설정함으로써 json 데이터와 매핑할 수 있습니다.
getter를 설정해줌으로써, {"id":"1", "review":"랄랄"} 이와 같이 getId(), getReview()메서드를 통해서 각각의 필드와 매핑이 되는 것입니다.
@Getter 어노테이션을 붙여줌으로써, json 데이터에 내보내는 필드명과 객체에 담긴 필드명을 손쉽게 일치시킬 수 있습니다.
만약 이 두 필드명이 불일치하다면, JsonProcessingException이 발생할 수도 있습니다.
또한 Getter 메서드를 기반으로 프로퍼티명을 확인하기 때문에,
postman을 사용하여 테스트할 경우에는 필드명이 일치하는지 꼭꼭 확인할 필요도 있습니다!(자주 발생했던 실수입니다)
만약 @Getter 어노테이션이 아닌 메서드를 직접 정의하고, 2번처럼 return 값을 고정시켜놨다고 가정해보겠습니다.
//1. 일반적인 getter 메서드
public int getAge(Entity entity) {
return this.age;
}
//2. 값을 고정한 getter 메서드
public int getAge(Entity entity) {
return 23;
}이런 경우 json 데이터 변환작업이 이뤄진다면 json 데이터에도 {"age" : 23} 이렇게 담겨진다고 합니다.
이런 상황을 통해서 getter의 역할을 알 수 있습니다.
1. getter는 매핑관계를 설정해줄 수 있습니다.
2. 직렬화를 통해 json 데이터를 내보낼 때, getter의 return값을 데이터로 내보냅니다.
그렇기 때문에 json 변환에 있어서 getter는 빠져서는 안되는 필수적인 어노테이션이라는 것을 알 수 있습니다.
결론부터 말하자면, 저희 프로젝트의 변환작업에서 기본생성자는 있어도 되고, 없어도 되는 어노테이션이라고 생각했습니다.
ObjectMapper가 데이터 바인딩을 하기 위해서는,
1. 기본 생성자를 통해서 새 객체를 생성합니다.
2. getter, setter 혹은 public field 등을 통해서 프로퍼티명을 찾습니다.
3. java.lang.reflection 패키지를 통해 값을 주입합니다.
이런 과정을 거쳐야 합니다.
그렇기 때문에 @NoArgsConstructor를 통해서 기본 생성자를 만들어줬습니다.
그러나 기본 생성자가 없어도 이런 변환작업은 가능하다고 합니다.
ObjectMapper 내부에는 property와 생성자가 위임된 경우 그 정보를 이용해서 직렬화/역직렬화에 사용하는 로직이 있습니다.
위임 어노테이션에는 @JsonProperty, @JsonAutoDetect, @JsonCreator가 있습니다.
여기서 위임이라는 것은 어노테이션을 사용해 객체를 변환(직렬화/역직렬화)할 때 쓰일 정보를 직접 선언하는 것인데,
이 위임을 자동으로 해주는 jackson-datatype-jdk8이라는 라이브러리가 있습니다.
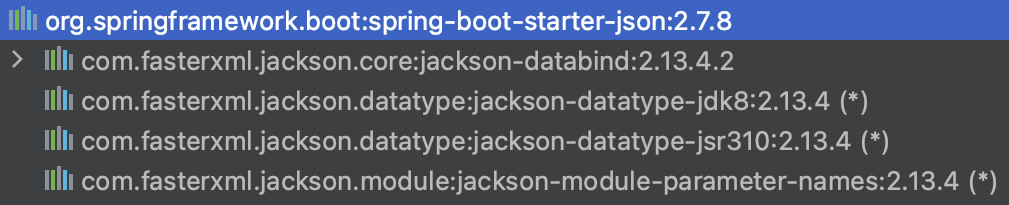
현재 저희의 프로젝트에도 포함되어 있습니다. 위의 3가지 모듈을 모두 지원해주고 있습니다.
여기에서 @JsonProperty 어노테이션을 통해서 jackson-module-parameter-names 모듈을 지원받을 수 있습니다.
이 모듈은 기본 생성자가 없어도 다른 생성자로 대체하여 역직렬화를 수행할 수 있다고 합니다.
SpringBoot에서는 jackson binding을 할 때 ObjectMapper에 이 모듈이 기본적으로 등록되어 있다고 합니다.
그래서 controller에 들어오는 request dto에 기본생성자가 없어도 역직렬화를 수행할 수 있습니다.
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| 왜 외래키가 있는 곳을 연관관계의 주인으로 잡을까? (0) | 2023.03.21 |
|---|---|
| javax에서 jakarta로 변경 (0) | 2023.03.21 |
| [SpringBoot]변수명으로 인한 mustache문제 해결 (0) | 2022.05.29 |
| [SpringBoot] Spring Security와 OAuth 2.0(1) (0) | 2022.05.26 |
| [SpringBoot] WSGI와 CGI (0) | 2022.05.08 |
스프링부트 JPA 강의를 수강하면서, 왜 하필 외래키가 있는 곳을 연관관계의 주인으로 잡는지에 대한 의문이 생겼습니다.
결론부터 말하자면, 성능상의 이점이 가장 큰 것 같습니다.
일대다(1:N) 연관관계를 가지는 자동차와 바퀴 4개를 예시로 들어보겠습니다.
먼저, 외래키를 왜 다(N)에서 가져야 하는지에 대해 알아보겠습니다.
외래키는 일(1)이 가질수도 있고, 다(N)에서 가질수도 있습니다.
그러나 이런 경우는 외래키를 제외한 나머지 필드 데이터들의 중복 문제가 발생할 수도 있습니다.
이 외에도 다양한 문제점들이 있기 때문에, 일반적으로 다(N)에서 외래키를 가지게 하는 것입니다.
다(N)쪽이 외래키를 관리하게 된다면 위와 같은 중복 문제도 피할 수 있기 때문입니다.
'다(N)쪽이 외래키를 가지게 하는 것이 좋다'
이제 바퀴 테이블이 외래키를 가지고 있습니다.(외래키 = 자동차의 id)
다음으로 연관관계의 주인이 어떤 것인지 알아보겠습니다.
연관관계의 주인이란, 양방향 관계를 가진 두 개의 테이블이 있을 때 데이터의 변경을 책임지는 역할을 합니다.
즉 외래키 관리자라는 뜻입니다.
그래서 연관관계의 주인이 된다면, 등록/수정/삭제 작업이 일어날 때 직접 데이터를 관리할 수 있습니다.
반면 연관관계의 주인이 아닌 테이블은 직접적으로 관리하지 못하고, 오직 읽을수만 있게 됩니다.
자동차가 연관관계의 주인이라면, 바퀴의 값이 바뀌는 상황이 있을 때 바퀴 테이블을 자동차 테이블이 직접 관리해줘야 합니다.
이는 불필요하게 복잡해질 수도 있고, 외래키 무결성 제약 조건에 위반될 수도 있습니다.
바퀴가 연관관계의 주인이라면, 자신의 데이터를 직접 스스로 해결할 수 있게 됩니다.
'외래키를 가진 쪽이 연관관계의 주인이 되는 것이 좋다'
왜 외래키가 있는 곳을 연관관계의 주인으로 잡을까?에 대한 질문은 위의 내용을 토대로,
"다(N)쪽이 외래키를 가지는 것이 좋고, 외래키를 가진 쪽이 연관관계의 주인이 되어야 한다" 는 결론을 내릴 수 있을 것 같습니다.
아직 많은 테이블 설계를 해보지 못했고, 상황에 따라 달라지는 경우도 있다고 합니다.
그러나, 일반적인 사실이라는 것을 미뤄봤을 때 ERD의 기본적인 설계는 이를 토대로 해야겠다고 생각했습니다.
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| 왜 dto에서 항상 @Getter와 @NoArgsConstructor를 붙여줘야 할까? (0) | 2023.03.26 |
|---|---|
| javax에서 jakarta로 변경 (0) | 2023.03.21 |
| [SpringBoot]변수명으로 인한 mustache문제 해결 (0) | 2022.05.29 |
| [SpringBoot] Spring Security와 OAuth 2.0(1) (0) | 2022.05.26 |
| [SpringBoot] WSGI와 CGI (0) | 2022.05.08 |
스프링부트 버전을 대부분 2로 시작하는 버전만 사용하다가, 최근 3.0.4버전으로 프로젝트를 생성했습니다.
버전이 변경되도 별 차이가 없다고 생각했는데, @NotEmpty validation을 체크하려다가 변경된 사항을 확인했습니다.
기존에는 option + enter만 눌러도 바로 validation 라이브러리가 import가 되었지만, 변경된 버전에서는 build.gradle에 의존성을 따로 추가해줘야했습니다.
implementation 'org.springframework.boot:spring-boot-starter-validation'이렇게 함으로써, validation 어노테이션들이 잘 적용되는 걸 확인했습니다.
Reference
Hibernate validator @NotEmpty not working spring boot and jackson
I have the following class which has errorRequests with @NotEmpty annotation. public class ErrorsRequests implements Serializable { private static final long serialVersionUID = -727308651190295...
stackoverflow.com
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| 왜 dto에서 항상 @Getter와 @NoArgsConstructor를 붙여줘야 할까? (0) | 2023.03.26 |
|---|---|
| 왜 외래키가 있는 곳을 연관관계의 주인으로 잡을까? (0) | 2023.03.21 |
| [SpringBoot]변수명으로 인한 mustache문제 해결 (0) | 2022.05.29 |
| [SpringBoot] Spring Security와 OAuth 2.0(1) (0) | 2022.05.26 |
| [SpringBoot] WSGI와 CGI (0) | 2022.05.08 |
'스프링부트와 AWS로 혼자 구현하는 웹서비스' 책을 보며 실습을 하면서 해결되지 않는 문제가 하나 있었다.

분명 코드를 다시 검토해보기도 하고, 저자의 github을 아예 복붙하는 방법도 해봤다. 원래는 Logged in as: [내 이름]이 떠야 하는데, 내 이름이 아닌 User라고 떴다. 아래는 책과 똑같은 코드이다.
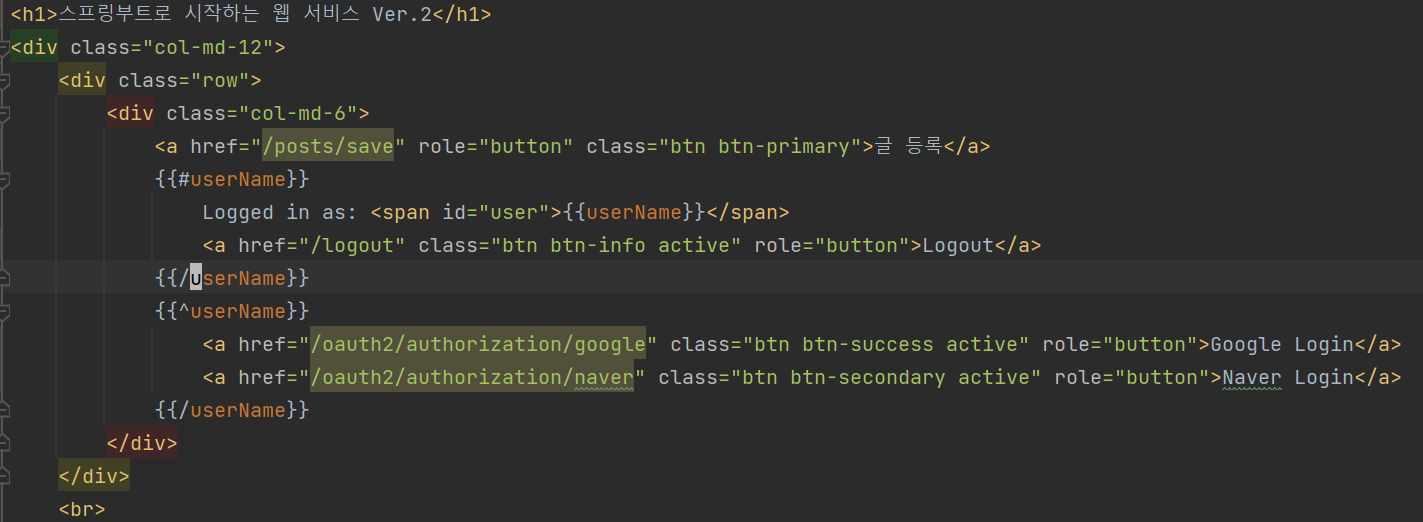

값은 잘 받아오는 것을 디버깅하여 확인하였기 때문에 mustache파일에 문제가 있다고 생각하였지만 전혀 다른 부분은 없었다. 그러다가 같은 문제를 겪은 분이 있는 걸 알았다.
https://github.com/saechimdaeki/Spring_boot_AWS/issues/2 👍
mustache에서 userName 변수로 값을 넘길경우 생기는오류 해결 : · Issue #2 · saechimdaeki/Spring_boot_AWS
window OS사용시 userName으로 값을 주고받을시 윈도우 사용자명이 출력됨. window 사용자의경우 변수를 변경하자 . ex) userName -> loginuserName 💯
github.com
WindowOs환경에서는 userName으로 값을 주고받을 시 윈도우 사용자명이 출력되기 때문에 내 이름이 나오지 않았던 것이다!

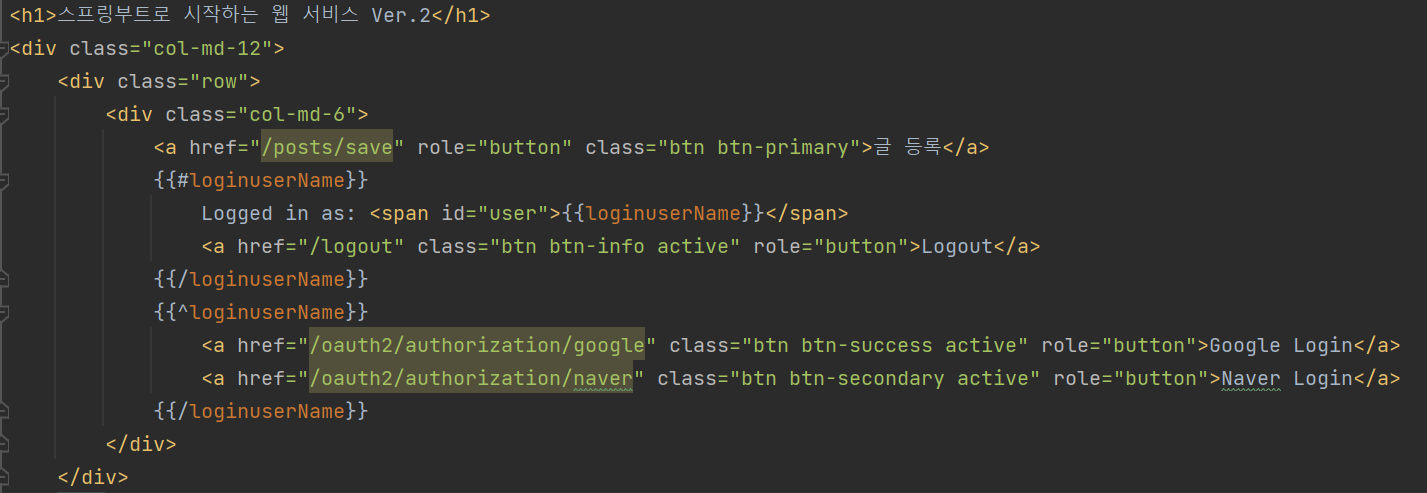
user에서 내 이름이 뜬 걸 확인할 수 있다!
'개발 공부 기록 > 스프링부트 스터디' 카테고리의 다른 글
| 왜 외래키가 있는 곳을 연관관계의 주인으로 잡을까? (0) | 2023.03.21 |
|---|---|
| javax에서 jakarta로 변경 (0) | 2023.03.21 |
| [SpringBoot] Spring Security와 OAuth 2.0(1) (0) | 2022.05.26 |
| [SpringBoot] WSGI와 CGI (0) | 2022.05.08 |
| [SpringBoot] @SpringBootTest의 webEnvironment 속성 (0) | 2022.05.08 |
이 단원을 공부하기에 앞서 간략히 알아야 하는 명령에 대해서 정리를 하였다.
<파일 검색하는 데 사용되는 명령어>
locate :: 파일명으로 파일 위치 찾기
find :: 디렉토리 트리 내에서 파일 검색하기
<파일 검색 결과를 처리하는 데 사용되는 명령어>
xargs :: 표준 입력으로부터 인자 목록을 만들고 실행하기
touch :: 파일 시간을 변경하기, stat :: 파일이나 파일 시스템 상태 표시하기
> locate
- locate bin/zip → bin/zip 문자열이 포함된 결과를 보여줄 것이다.
- locate zip | grep bin → zip과 bin 문자열이 포함된 결과가 출력될 것이다.
*grep 명령어 : 특정 파일에서 지정한 문자열이나 정규표현식을 포함한 행을 출력해주는 명령어이다(내가 원하는 문자열이 있는 라인을 찾을 수 있다)
| 파이프를 사용하면, grep 명령어를 여러 개 사용할 수 있다.
> find
locate는 오로지 파일명에 근거하여 파일을 찾을 수 있지만, find는 다양한 속성에 근거하여 주어진 디렉토리를 검색하여 파일을 찾는다. find의 훌륭한 점은 특정조건에 부합하는 파일을 찾아낼 수 있다(조건을 상세하게 설정가능하다)
1. 파일 형식에 따른 조건 지정
- find ~ type d | wc -l → 디렉토리 검색으로 제한, 디렉토리 개수 출력
- find ~ type f | wc -l → 파일 검색으로 제한, 파일 개수 출력
2. 파일 크기, 파일명 검색 조건 지정
- find ~ -type f -name "*.JPG" -size +1M | wc -l → 와일드카드 패턴 *.JPG와 일치하며, 1MB보다 큰 파일 검색, 개수 출력
* :: test를 말한다. find의 명령어의 test는 훨씬 더 많다. 더 많은 test는 find의 man페이지를 확인하면 볼 수 있다.
* +, -, (생략) ::
+ → 지정한 파일 크기보다 큰 파일로 검색한다.
- → 지정한 파일 크기보다 작은 파일로 검색한다.
(생략) → 지정한 파일 크기와 정확히 일치하는 파일로 검색한다.
>연산자
모든 테스트들조차도 테스트 간의 논리적인 관계를 설명하기 위한 더 나은 방법이 필요할 수도 있다.
- -and :: 연산자를 기준으로 양쪽 테스트 조건이 모두 참인 경우에 검색된다. 아무런 연산자를 입력하지 않는다면 기본값으로 -and가 적용된다. 줄여서 -a로 적을 수도 있다.
- -or :: 양쪽 테스트 중 하나라도 참인 경우에 검색된다. 줄여서 -o로 적을 수도 있다.
- -not :: 연산자 다음에 나오는 테스트가 거짓인 경우에 검색된다. -!로 적을 수도 있다.
- ( ) :: 테스트와 연산자를 하나로 조합하여 표현한 내용을 하나로 그룹화할 때 사용된다. 명령어의 가독성을 높이기 위해 사용하기도 한다. 보통 백슬래쉬와 괄호와 함께 사용한다.
예를 들어서, 디렉토리 내의 모든 파일과 하위 디렉토리가 안전한 권한을 가지고 있는지 확인해야 할 경우,
→ 해당 파일들의 퍼미션인 0600으로 설정되어 있는지, 해당 디렉토리의 퍼미션이 0700으로 설정되어 있는지에 대해 확인할 필요가 있다.
→ 이를 논리연산자를 사용하여 판단할 수 있다.
- find ~ \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
잘못 설정된 파일과 디렉토리를 찾는 것인데, 왜 -and가 아닌 -or로 연결되어 있을까? find명령어가 파일과 디렉토리를 모두 탐색하면서 지정된 테스트에 대한 일치 여부를 하나하나 계산하기 때문이다.
expr1 -operator expr2_[연산자 로직]
- -operator가 -and일 경우 : expr1이 참이면, expr2가 실행한다 / expr1이 거짓이면, expr2가 실행하지 않는다.
- -operator가 -or일 경우 : expr1이 참이면, expr2는 실행하지 않는다/ expr1이 거짓이면, expr2는 실행한다.
왜 이런 로직으로 작동할까? 검색 성능을 개선하기 위해서이다.
> 액션
find명령의 결과 목록 출력은 유용하지만, 정말로 하고자 하는 것은 해당 목록에 있는 항목들을 동작하는 것이다.
액션에는 미리 정의된 액션과 사용자 지정의 액션이 있다.
미리 정의된 액션에는 -ls, -print, -delete, -quit 등이 있다.
- find ~ → 홈 디렉토리에 잇는 모든 파일 및 하위 디렉토리 목록을 보여준다. 사실 이는 -print 액션이 함축된 것이다. 별도의 액션 언급이 없으면 기본값으로 -print액션이 실행된다. (= find ~ -print)
- find ~ -type f -name '*.BAK' -delete → 사용자의 홈 디렉토리에 있는 모든 파일에 대하여 .BAK으로 끝나는 파일명을 검색하고, 해당 파일을 찾게 되면 모두 삭제된다.
- find ~ -type f -and -name '*.BAK' -and -delete → -and연산자는 언급되지 않으면 기본값으로 수행된다.
- -delete 는 find ~ type f와 -name '*.BAK'의 결과가 참인 경우에 수행된다.
- -name '*.BAK'은 find ~ -type f의 결과가 참인 경우에 수행된다.
- -type f는 항상 수행된다. -and관계에서 첫 번째 표현이기 때문이다.
사용자 지정의 액션은 임의의 명령어를 실행할 수도 있다. 대표적으로 -exec 액션을 활용한 명령이 있다.
-exec command { } ;
command자리에는 명령어의 이름이 들어가고, { }의 기호에는 현재 경로명에 대한 심볼릭 링크를 표시한다. 세미콜론은 명령어의 끝을 말해주는 구획 기호로 꼭 필요하다. 중괄호와 세미콜론은 Shell에서 특수한 의미로 사용되기 때문에 반드시 인용되거나 확장되어야 한다.
* 심볼릭 링크 :: 링크를 연결하여 원본 파일을 직접 사용하는 것과 같은 효과를 내는 링크이다. 심볼릭 링크를 따로 연결하는 방법은 타 블로그 주소를 첨부해놓겠다.
https://qjadud22.tistory.com/22
- find ~ -type f -name 'foo*' -ok ls -l '{}' ';' → 사용자 정의 액션을 대화식으로 실행하는 것도 가능하다 -ok 액션을 -exec자리 대신에 넣으면 지정된 명령을 실행하기 전, 사용자에게 확인 메시지를 뜬다. 'y'를 입력하면 출력되고, 'n'를 입력하면 출력되지 않는다.

-exec 액션을 사용하면, 일치하는 파일이 발견될때마다 지정된 명령을 매번 실행한다. 이런 반복성을 효율적으로 수행하기 위한 대안법이 2가지가 있다. 하나는 xargs라는 외부 명령어를 사용하는 것이고, 다른 하나는 find가 가진 새로운 기능을 활용하는 것이다.

위의 명령은 기존에 예제로 했던 명령이다. 이 예제는 일치하는 파일이 발견될 때마다 ls 명령을 실행한다.

여기서 ';' 대신에 + 기호를 사용한다. 그러면 원하는 명령이 한 번에 실행될 수 잇도록 검색 결과들을 인자 목록으로 묶어주는 find의 기능이 활성화된다. 결과는 동일하지만, 여기서는 ls 명령이 한 번 실행된 것이다.

xargs 명령어를 사용해도 똑같은 결과를 얻을 수 있게 된다. xargs 명령은 표준 입력으로부터 입력을 받아서 지정한 명령어를 위한 하나의 인자 목록으로 변환한다.
> touch명령어
보통 파일이 수정된 시간을 갱신하거나 설정할 때 사용하지만 파일명 인자가 존재하지 않는 파일이라면 새로운 빈 파일을 만든다.
'개발 공부 기록 > 리눅스 커맨드라인 입문' 카테고리의 다른 글
| Pre-16. 네트워킹 이전 짚고가야할 개념 (0) | 2022.05.23 |
|---|---|
| 12. VI(브이아이) (0) | 2022.05.02 |
| 11. 환경 (0) | 2022.05.02 |
| 왜 리눅스 커맨드를 배워야 할까 (0) | 2022.05.02 |